68-я Всероссийская научная конференция МФТИ
Список разделов ФРКТ - Cекция высокопроизводительных вычислительных систем
На секцию высокопроизводительных вычислительных систем будут приниматься научные работы, посвященные проблемам и методам проектирования отечественных универсальных микропроцессоров и вычислительных комплексов, их аппаратуры и системного программного обеспечения. Основное внимание уделяется высокой производительности и защищенности вычислительного процесса, двоичной совместимости с доступными ресурсами прикладного программного обеспечения.
Контакты: surchenko_a@mcst.ru
Формат проведения: онлайн
Дата и время проведения: 03.04.2026 в 11:00
Место проведения: онлайн платформа
-

Реализация «Кузнечик» (ГОСТ Р 34.12-2015) на процессоре без аппаратного ускорения работает очень медленно. Разработан аппаратный модуль блочного шифра «Кузнечик» (ГОСТ Р 34.12-2015) для FPGA, Управление выполнено конечным автоматом, который запускает полное Испытания показали средние затраты 793 такта на установку ключа и 199 тактов на шифрование/расшифрование блока при 100 МГц
-

Детально описывается метод оценки производительности многоядерного процессора в больших задачах вроде тестов SPEC CPU путём воспроизведения на RTL-модели процессора трасс запросов в память, полученных на потактовом симуляторе процессора с использованием кластерной выборки.
-

Архитектура loongarch64 активно развивается в последние годы. Серверные ЦПУ Loongson 3C6000 на ядрах LA664 с 32, 64 и 128 потоками и частотой 2-2,2 ГГц показывают достойный уровень производительности, составляя конкуренцию процессорам других архитектур. В работе освещены особенности и возможности архитектуры loongarch64. Производительность Loongson последнего поколения оценивалась среди встраиваемых, настольных и серверных ЦПУ в ряде бенчмарков в сравнении с ЦПУ Эльбрус, Intel, AMD и ARM.
-

В работе представлена архитектура специализированного потокового векторного процессора для FPGA, предназначенного для ускорения нейросетевых вычислений. Модуль с параметризируемой SIMD-размерностью поддерживает векторные и матричные операции, обеспечивая высокую пропускную способность при минимальном использовании ресурсов. Решение ориентировано на энергоэффективную интеграцию в вычислительные платформы искусственного интеллекта.
-

Разработка и внедрение специализированных ускорителей для логического вывода нейросетевых моделей требует гибких и адаптируемых средств компиляции, способных учитывать архитектурные особенности целевого оборудования. В данной работе представлено описание механизма компиляции нейронных сетей, ориентированного на аппаратные платформы с тензорной архитектурой и специальным набором инструкций.
-

В работе рассматриваются особенности процедуры реконфигурации подсистемы памяти современных процессоров архитектуры "Эльбрус" при изменении настроек адресного пространства. Описываются оптимизации процесса синхронизации узлов сети-на-кристалле в рамках этой процедуры, произведенные при разработке последнего поколения процессоров.
-
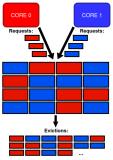
В работе рассматривается проблема конкуренции задач за общую кэш-память в многоядерных процессорах. Предлагается решение, позволяющее уменьшить число конфликтов между задачами за счет аппаратного разделения кэш-памяти на основе модификации политики замещения.
-

В работе рассматривается разработка контроллера проприетарной шины ELPLC-BUS для программируемого логического контроллера «Эльбрус» на базе ПЛИС, предназначенного для замены снятых с производства микросхем приёмопередатчиков UART. Представленная реализация обеспечивает поддержку высокоскоростного обмена по интерфейсу RS-485 и первичную обработку пакетов шины, что позволяет снизить нагрузку на микроконтроллер модуля ввода-вывода.
-
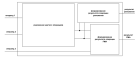
В работе рассматривается оптимизация аппаратных затрат устройства FMA процессора «Эльбрус» путем замены части унифицированных умножителей мантисс 64x64 бита на умножители разрядности 53x53 бита. Представлены результаты синтеза разработанных RTL-моделей, подтверждающие снижение площади кристалла при сохранении производительности и полной функциональности устройства.
-

В работе рассматривается разработка и адаптация открытого стека прошивки OpenBMC для контроллера управления базовой платой ASPEED AST2600 в составе серверных платформ на базе микропроцессора «Эльбрус». Предлагается решение, включающее создание специализированного слоя meta-mcst и комплексной системы автоматизированной сборки на базе Docker и bash-скриптов, обеспечивающее полную воспроизводимость результатов сборки, унификацию разработки и сокращение времени отладки прошивки BMC.