68-я Всероссийская научная конференция МФТИ
Список разделов ФПМИ - Секция технологий искусственного интеллекта
Секция посвящена проблемам искусственного интеллекта
Контакты: bulichev.ov@mipt.ru
Формат проведения:
Дата и время проведения:
Место проведения:
-

Исследована оптимизация ставок в закрытых Web3-аукционах (Polygon FastLane) методами Deep RL. В условиях нестационарности предложен агент на базе PPO с архитектурой History-Conditioned Policy. На датасете из 223 тыс. аукционов доказано, что учет контекста позволяет избежать «проклятия победителя». Разработанный подход превосходит индустриальный бенчмарк (MEV-X) по чистой прибыли на 43% и метрике MPC на 24%, демонстрируя высокую адаптивность к динамике конкуренции в реальном времени.
-

В работе исследуется возможность использования малой языковой модели для построения генеративных рекомендательных систем на основе семантических идентификаторов товаров, представляющих собой иерархическое семантическое пространство. Эксперименты, проведённые на датасете Amazon, показывают, что модель способна корректно воспроизводить структуру идентификаторов и сохранять высокоуровневую семантику товаров. Полученные результаты подтверждают перспективность подхода для рекомендательных сценариев.
-

Данная работа посвящена разработке архитектуры интеллектуального образовательного помощника на основе симбиоза графов знаний и больших языковых моделей (LLM). Граф знаний обеспечивает структурированное хранение фактов и связей между учебными понятиями. Большая языковая модель используется для обработки естественно-языковых запросов учащихся и генерации контекстных объяснений. Их совместное применение позволяет создать систему, которая даёт точные ответы и адаптирует подачу материала.
-

В рамках данного исследования разработан класс методов динамического контекстно-зависимого прунинга активаций больших языковых моделей для ускорения инференса на основе расстояния Махаланобиса
-

Исследовано обучение эмбеддингов спектров тандемной масс-спектрометрии для быстрого поиска похожих спектров без дорогостоящего попарного сравнения. Каждый спектр представлен графом: пики — узлы, рёбра задаются алфавитом разностей масс, что вносит структурную информацию в модель. Построена модель, сохраняющая структуру спектрального сходства и обеспечивающая согласованность спектров повторных измерений; при этом графовые модели устойчиво превосходят неграфовый базовый вариант.
-

Работа посвящена проблеме защиты семантического поиска. Предложен и теоретически обоснован гибридный двухуровневый метод, сочетающий необратимые SVD-проекции с секретной ортогональной ротацией для защиты базы данных и гомоморфное шифрование для защиты запроса. Эксперименты на корпусе из 1 млн документов русскоязычной Википедии показали эффективность данного метода. Метод ориентирован на корпоративные RAG-системы, медицинские и юридические базы знаний.
-

Обычно обучение генеративных моделей занимает очень долгое время (месяцы), а сами они очень тяжелые. Производители мобильных устройств внедряют генеративные сети для задач воспроизведения контента, игр и фоторедакторов. Для этого создаются специальные архитектуры для мобильных устройств. В работе предлагается метод, позволяющий оптимизировать уже существующие генеративные сети под мобильные устройства с минимальными временными затратами на дообучение.
-

В работе разработан воспроизводимый фреймворк глубокого обучения для автоматизированной детекции хромотрипсиса - катастрофического события геномной нестабильности, связанного с агрессивным течением рака. Проведен бенчмаркинг и оптимизация модели GECNVNet, а также предложены событийные модели BiLSTM и Graph-GNN для анализа структурных вариаций. Показано, что графовое представление SV точнее отражает топологию перестроек и улучшает качество классификации.
-

Предлагается алгоритм FGTS-LASSO для разреженных контекстных бандитов, разделяющий отбор признаков и оценку награды. LASSO выделяет релевантную поддержку для каждого действия. Затем на выбранных признаках строится байесовская линейная модель с гауссовским апостериором. Эксплорация выполняется через Thompson Sampling — семплирование параметров и выбор лучшего действия. При стандартных предположениях достигается регрет $${\rm O}\left(\frac{s}{\sqrt{T}}\right) при s\ll d$$.
-

Исследуется применение сетей Колмогорова–Арнольда для моделирования табличных данных. Анализируется влияние эмбеддингов численных признаков и алгоритма оптимизации на качество обучения. Эксперименты проведены на публичных задачах классификации и регрессии при едином протоколе настройки моделей. Показано, что эмбеддинг PLE-Q улучшает качество, а оптимизатор Muon обеспечивает лучшую сходимость по сравнению с AdamW и альтернативами. Рекомендуется сочетание «KAN + PLE-Q» и Muon.
-

В данной работе предлагается метод персонализированной предкомпенсации изображений при аномалиях рефракции на основе модифицированных нейронных сетей с двумя входами, принимающих изображение и функцию размытия точки (ФРТ). Предложенный подход обеспечивает более высокое качество восстановления ретинальных изображений и существенно меньшее время обработки по сравнению с существующими аналитическими и оптимизационными методами.
-

В работе исследуется способность современных больших языковых моделей (LLM) интерпретировать пространственную информацию в среде Crafter. Для оценки разработан специализированный датасет Crafter-Perception (1400 вопросов). Эксперименты с моделями Qwen2.5, GPT-4o и Claude 3.5 Sonnet показали, что задачи на определение координат и дистанции вызывают значительные трудности даже у SOTA-моделей, а дообучение с подкреплением (RL) не приводит к улучшению перцептивных способностей агента.
-

В этой работе исследуется архитектура Hyper-Connections — модификация трансформера с несколькими параллельными residual-потоками. Показано, что на практике смешивание потоков используется слабо: уже после первых слоёв они почти не взаимодействуют, а обновления быстро концентрируются в одном доминирующем потоке. На основе этого анализа мы предлагаем простой обучаемый механизм, который улучшает использование нескольких потоков и повышает качество модели без увеличения вычислительных затрат.
-

Исследована интерпретация стратегий Го на базе малых языковых моделей (SLM). Сформирован уникальный датасет из 363 тыс. позиций, объединяющий сигналы алгоритма KataGo и экспертные аннотации. Предложен метод генерации пояснений через дообучение моделей Qwen и Gemma. Экспертная оценка с участием игроков уровня МС (5 дана) подтвердила достижение моделью человекоподобной естественности речи и высокую стратегическую и обучающую ценность генерируемых объяснений.
-

Исследуется эффективность ряда состязательных атак на модели машинного обучения в задаче анализа сетевого трафика для выявления методов, максимизирующих деградацию качества IDS при заданных ограничениях. Полученные результаты показали, что итеративная атака PGD обеспечивает наилучший баланс между снижением точности целевой модели и временными затратами, в то время как black-box методы ZOO и HSJA достигают сопоставимой деградации качества, но ценой на порядок больших вычислительных ресурсов.
-

В работе рассматривается улучшение модели UserBERT для задач антифрода. Основная идея состоит в добавлении новой сложной модальности, которая содержит дополнительное совместное описание объектов типа query и document. Это расширение позволило повысить качество бинарной классификации и сделать модель более чувствительной к сложным мошенническим сценариям.
-

В работе предложен подход к распознаванию русского жестового языка на основе скелетных данных кистей рук, в котором жест представлен как последовательность графов ключевых точек. Разработана модифицированная графовая нейронная сеть, обеспечивающая сопоставимое качество распознавания при меньшей вычислительной сложности по сравнению с методами, основанными на видеоданных. Устойчивость модели подтверждена результатами тестирования на наборах данных жестовых языков разных стран.
-

Предложен двухэтапный метод восстановления энергетического спектра нейтронов по откликам многошарового спектрометра Боннера на базе ANFIS. На первом этапе минимизируется ошибка реконструкции, на втором вводятся SHAP-регуляризация интерпретируемости и тихоновская регуляризация гладкости спектра. Метод уменьшает нефизичные осцилляции и сохраняет объяснимость.
Результаты: R2_weighted≈0.84, RMSE≈0.10, стабильность подтверждена Monte Carlo (1000 прогонов, шум 0.5–10%). -

Предложена компактная спайковая нейронная сеть с вероятностными нейронами и корреляционным обучением на основе STDP для задач классификации. Проведено сравнение трех моделей пластичности: аддитивной STDP и двух мемристорных: нанокомпозитной и поли-п-ксилиленовой. Показано, что STDP можно заменить мемристорными правилами без потери качества, а модель использует на порядок меньше синапсов по сравнению с похожими работами, что делает ее пригодной для реализации на мемристорном оборудовании.
-

В докладе описывается мультиагентная система, основанная на больших языковых моделях, разработанная для автоматизации процесса анализа и выявления закономерностей в адаптационных тестированиях. Описывается архитектура и принцип работы системы, также описывается процесс тестирования модели на реальных и синтетических данных.
-

Представлен метод эволюционной оптимизации промптов для адаптации LLM-разметчиков без дообучения. Алгоритм AlphaEvolve итеративно улучшает промпт на основе анализа ошибок ансамбля на gold-выборке. В ходе циклов сложные примеры переводятся в разряд якорных за счет генерации динамических правил. Подход повышает качество разметки в узких доменах без обновления весов модели.
-

В работе предлагается ClarifySAE — метод управления поведением больших языковых моделей через интерпретируемые признаки, выделенные с помощью разряженного автоэнкодера без изменения весов модели. Признаки ранжируются по ClarifyScore и фильтруются по OutputScore. Оценка на AmbiK и ClarQ-LLM для моделей Gemma (2B, 9B) показывает, что на AmbiK с Gemma-2-9B-IT доля уточняющих вопросов возрастает с 0,61 до 0,95, а успешность выполнения — с 0,06 до 0,21.
-

В работе предлагается метод Semantic Valency Conflict (SVC) для детектирования семантической неоднозначности в инструкциях на естественном языке для воплощённых агентов. Подход основан на моделировании конфликта между валентными профилями, активируемыми конкурирующими когнитивными фреймами одной лексемы. Метод объединяет идеи фреймовой семантики и теории валентности с возможностями больших языковых моделей.
-

Работа исследует методы дообучения малых языковых моделей для решения сложных математических задач. Предложен протокол, объединяющий GRPO и обучение с постепенным усложнением, что снижает вычислительные затраты за счёт отказа от модели-критика и поэтапного усложнения задач, напоминающее обучения человека и поддерживающее стабильное обучение. Эксперименты показывают, что такой подход позволяет компактной модели стабильно формировать цепочки рассуждений при сохранении низкой KL-дивергенции.
-

Цель работы - количественно оценить влияние BF16-аккумулирования (округление частичных сумм в BF16) в матричных операциях на точность трансформерного детектора YOLOS и разработать подход к адаптации модели под целевую арифметику. Реализована эмуляция BF16-accum для self-attention и линейных проекций и предложена схема дообучения BF16-accum. Установлено, что полный режим BF16-accum снижает AP на 2.88 п.п., а предложенная адаптация восстанавливает до 0.86 п.п.
-

В работе предложен метод анализа визуальных энкодеров на основе реконструкции изображений из латентных представлений. Обученная модель-реконструктор позволяет сравнивать информативность признаков различных архитектур и исследовать организацию информации в их латентном пространстве. Показано, что линейные преобразования в пространстве признаков реализуют интерпретируемые семантические изменения на уровне пикселей (подавление каналов, колоризация, выделение объектов по классам).
-

В работе рассматривается задача кластеризации последовательностей событий, представленных как реализации временного точечного процесса. Предлагается архитектура на основе единой LSTM-модели, в которой различные кластеры задаются обучаемыми начальными скрытыми состояниями. Обучение модели осуществляется в рамках EM-алгоритма, где максимизируется ожидаемое полное лог-правдоподобие смеси интенсивностей временного точечного процесса.
-

В работе представлена система автоматизированной предразметки и интеллектуальной фильтрации данных для обучения детекторов объектов в задачах мониторинга с БПЛА. Предложенный подход, сочетающий детекцию YOLO, кластеризацию эмбеддингов и семантический отбор через VLM. Данная система позволяет ускорить работу разметчиков с 4 до 1 месяца, обеспечивая эффективное масштабирование процесса обучения моделей компьютерного зрения
-

В работе исследованы современные методы диагностики технического состояния промышленного оборудования на основе вибраций, токов и температур. Проведён сравнительный анализ классических методов обработки сигналов и алгоритмов машинного обучения от CNN до Transformer-архитектур. Рассмотрены вопросы адаптации моделей к реальным производственным условиям, устойчивости к шуму. Результаты позволяют сформировать рекомендации выбора оптимального подхода в зависимости от типа оборудования.
-
Современные рекомендательные системы сталкиваются с проблемой несоответствия между запросами пользователей и метаданными треков. Предложен метод адаптивного взвешивания векторных пространств, основанный на классификации типа запроса (эмоция, контекст, теги). Подход улучшает релевантность выдачи за счёт динамического комбинирования результатов поиска по разным атрибутам.
-

В работе исследуется задача параллельной многомасштабной локализации объекта по изображению местности для систем навигации подвижных объектов в условиях нестабильности сигналов ГНСС. Предложен подход на основе сиамских нейронных сетей с энкодером EfficientNetB0 и фреймворком TensorFlow, обеспечивающий формирование инвариантных векторных эмбеддингов и оценку схожести изображений при вариациях ракурса, масштаба и условий съёмки.
-

Разработан метод DMM для задачи децентрализованного мультиагентного поиска путей (MAPF), решающий проблему нескоординированных действий агентов в конфликтных ситуациях. Предложен механизм итеративного совместного сэмплирования в пространстве логитов непосредственно в ходе коммуникации между агентами. На бенчмарке POGEMA показано, что подход повышает точность выбора бесконфликтных действий и способствует уменьшению числа столкновений агентов.
-

Традиционные подходы к сегментации диалогов показывают неплохие результаты на синтетических или письменных диалогах, но страдают при работе с устными, зашумленными диалогами, а также требуют тщательной настройки гиперпараметров. Мы предлагаем использовать новый подход, основанный на кратких описаниях диалогов. Эксперименты на различных наборах данных показали, что новый подход превосходит популярные современные алгоритмы в сегментации тем без учителя и требует меньших затрат на подготовку.
-

В работе рассматриваются техники федеративного обучения, нивелирующие его узкие места. Сжимающий оператор позволяет уменьшать нагрузку на отдельные каналы, а неполное участие не перегружает сервер. Мы рассматриваем два дизайна учета ошибок от искажения данных, в PPEF компенсация идет независимо, в SPPEF используется многоуровневая схема. Второй подход позволяет достигнуть оптимальную зависимость в члене O(1/$$\varepsilon^3$$), экспериментально выражающуюся в более быстрой начальной сходимости.
-
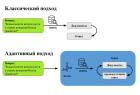
В работе исследуется адаптивный RAG, где LLM-агент решает, нужен ли поиск во внешней базе для ответа на запрос. Эксперимент на датасете MuSiQue показал, что использование порога уверенности модели для вызова инструмента поиска значительно повышает точность ответов. Для GPT-4o-mini с доля верных вызовов инструмента поиска выросла с 0.87 до 0.92, а доля ложных срабатываний вызова инструмента снизилась с 0.46 до 0.39, позволив сравняться с более мощной моделью grok-4.1-fast.
-

Задача визуального вопросно-ответного анализа (VideoQA) заключается в генерации ответа на текстовый вопрос, заданный пользователем, на основе визуального содержания видеоролика. В рамках данной работы рассматривается подход, в котором мультимодальные языковые модели (MLLM) применяются для анализа и интерпретации семантического содержания ключевых сцен видеоролика.
-

Работа посвящена кооперативной многоагентной навигации роботов в условиях частичной наблюдаемости: кооперативная стратегия сначала предобучается в симуляции, а затем используется для генерации управляющих последовательностей в MPPI. Эксперименты на круговых сценариях показывают, что предложенный метод повышает долю успешных прохождений и снижает количество столкновений по сравнению с существующими методами.
-

Исследуется масштабируемость многоагентных систем на базе больших языковых моделей. В вычислительном эксперименте (33 520 задач, 149 млн токенов) показано, что архитектура «спектральная иерархия» масштабируется до 256 агентов без деградации качества и без роста координационных затрат. Обнаружено эмерджентное формирование многоуровневой иерархии агентов при решении задач с межэтапными зависимостями. Проведён сравнительный анализ четырёх моделей различных разработчиков.
-

Ускорение инфренса больших языковых моделей за счет изменения структуры vLLM и использования метода EAGLE-3 для более точных предсказаний, и пакетной обратботки для полной утилизации GPU.
-
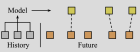
Работа предлагает модификацию модели долгосрочного прогнозирования последовательностей событий Detection-based Temporal Point Processes: вместо сжатия всей истории в один вектор предлагается использовать трансформерный декодер по аналогии с DETR, что позволяет каждой предсказательной голове индивидуально обращаться к истории событий. Ожидается, что это улучшит точность и разнообразие долгосрочных прогнозов.
-

Работа посвящена активному построению трёхмерной семантической карты мобильным роботом на основе представления сцены в виде набора анизотропных гауссиан (3D Gaussian Splatting). Предлагается подход, объединяющий активный выбор позиции наблюдения и хранение семантической информации в виде векторных признаков открытого словаря. Критерий выбора следующей точки учитывает ожидаемое уточнение геометрических и семантических параметров модели. Оценка проводится на сценах из Replica и Matterport3D.
-

В работе исследуется проблема ускорения МРТ-реконструкции в условиях отсутствия полного k-space (при наличии только разреженной амплитуды). Разработан пайплайн, объединяющий условные генеративные модели для синтеза недостающей фазовой информации с современными SOTA-моделями реконструкции. Показано, что формирование псевдо-комплексного k-space за счет восстановленной фазы позволяет значительно улучшить качество итоговых снимков по сравнению с методами, работающими исключительно с амплитудой.
-

Для преодоления проблем, возникающих при применении RL-алгоритмов в условиях разреженного и нерегулярного спроса, предложены две их адаптации: Hurdle A2C и SAC с моделью спроса. Экспериментально показано, что оба подхода превосходят классические стратегии управления запасами и исходные версии алгоритмов. Работа подтверждает перспективность применения RL в задаче управления запасами.
-

Работа посвящена анализу достоверности больших языковых моделей по отношению к генерируемым ими промежуточным структурам рассуждений. Предлагается формальная каузальная постановка задачи и вводится набор метрик, основанных на интервенциях, позволяющих количественно оценивать степень причинной зависимости между промежуточным представлением и итоговым ответом модели. Подход тестируется на задаче Text-to-SQL, что позволяет сделать выводы о степени управляемости и интерпретируемости современных LLM.
-

В современном мире задача обнаружения и отслеживания БПЛА в видеопотоке остается актуальной в контексте предотвращения нарушения охраняемого периметра БПЛА – нарушителем. Часто в подобных задачах в качестве платформы для камеры также используются БПЛА, оснащенные слабым бортовым вычислителем без графического процессора. Этот факт накладывает ограничения на выбор архитектур. В данной работе представлена архитектура мультикамерного обнаружения и отслеживания БПЛА для встраиваемых систем.
-

В работе рассматриваются недостатки текущих подходов спекулятивного декодирования. На их основе предлагается использование техники раннего прекращения вычислений без необходимости предобучать модель. Используется совместная оптимизация числа одновременно обрабатываемых запросов и числа генерируемых черновой моделью токенов, уменьшающая время генерации одного токена и увеличивающая пропускную способность системы. Полученные результаты подтверждают перспективность предложенных методов.
-

Исследована проблема снижения эффективности спекулятивного декодирования в архитектуре Mixture of Experts (MoE). С помощью метрики Target Efficiency аналитически и экспериментально (на модели Qwen3) доказано, что узким местом для MoE является этап верификации: увеличение числа черновых токенов приводит к перегрузке памяти из-за активации множества экспертов, что нивелирует ускорение.
-

Работа посвящена методу SimplexLoRA для динамического перераспределения размерностей адаптеров LoRA через проекцию на симплекс. Перераспределение происходит на фазе калибровки, занимающей менее 1% времени обучения. После калибровки запускается стандартный пайплайн дообучения LoRA с новыми зафиксированными рангами. Метод повышает точность дообучения больших языковых моделей, не изменяя количество обучаемых параметров, и сохраняет обратную совместимость со стандартным методом LoRA.
-

Работа посвящена исследованию влияния формата квантования активаций на эффективность применения ортогональных вращений в больших языковых моделях. Рассматриваются современные форматы представления активаций и анализируется их совместимость с методами вращений, используемыми для повышения качества квантованных моделей.
-

В данной работе представлен алгоритм семантического анализа на основе машинного обучения и больших языковых моделей, предназначенный для поиска функциональных клонов 4-го типа в исходном и бинарном коде
. Предложенный метод объединяет многоэтапную генерацию контекста (анализ типов, суммаризация и анализ семантики) с использованием дообученной модели (LoRA) для формирования высокоуровневых концептуальных описаний функций . -

Хотя в классических ансамблевых методах модели обучаются независимо друг от друга, в данной работе исследуется гибридный подход, объединяющий независимое обучение с оптимизацией совместной функции потерь. Этот подход оказывается эффективен в федеративном обучении
Для решения задачи предлагается алгоритм FEEN. В экспериментах FEEN превосходит базовые подходы как в классическом обучении ансамблей, так и в сценариях федеративного обучения
-

-
 Ансамблевые методы и анализ архитектур сетей Колмогорова–Арнольда для моделирования табличных данных
Ансамблевые методы и анализ архитектур сетей Колмогорова–Арнольда для моделирования табличных данныхПроведен сравнительный анализ трех реализаций сетей Колмогорова–Арнольда (KAN): B-сплайны, RBF, полиномы Чебышева. Классический B-сплайн KAN показал наилучшую устойчивость (средний ранг 1.56±0.50 на 9 бенчмарках). Предложен параметр-эффективный метод ансамблирования KANM-mini, который превосходит TabM-mini (55.6% побед) и сопоставим с XGBoost. Результаты подтверждают перспективность KAN для табличных задач.
-

Работа посвящена исследованию интерпретируемости больших языковых моделей и механизмов возможны атак на них с прямым доступом к весам. Целью атак является изменение поведения модели при ответе на вредоносные запросы с отказа отвечать на внятный ответ. Рассматриваются методы направления отказа и адаптируются базовые методы из сферы редактирования знаний.
-

Способности LLM критически деградируют при агрессивной квантизации весов (2-3 бита на вес) существующими алгоритмами послойной квантизации. В представленном методе используется модификация послойной функции потерь и новый подход к оптимизации квантованных весов, что позволяет значительно уменьшить потерю качества работы моделей после применения сжатия.
-

В работе исследуются неслоистые резервуарные структуры в спайковых нейронных сетях для задач анализа временных данных. Резервуарный рекуррентный слой формирует временные признаки за счёт интеграции входного потока и внутренней динамики. Рассматриваются два варианта: резервуар как самостоятельный слой и гибридная схема со спайковыми свёрточными блоками перед резервуаром. Обучение выполняется с суррогатным градиентом и усечённой развёрткой во времени. Показано преимущество гибридной схемы.
-

Предложена модульная система автоматического преобразования аудиозаписей в нотный лист с текстом песни. Система объединяет разделение источников звука, полифоническую транскрипцию, генерацию фортепианной аранжировки моделью PiCoGen2 и гибридное выравнивание текста на основе музыкальных баз данных и модели распознавания речи. Разработаны алгоритмы квантизации MIDI и разделения партий рук методом динамического программирования, а также фильтр галлюцинаций на музыкальном аудио
-

Предлагается модуль на базе визуально-языковых моделей для автоматической классификации сбоев в роботизированной манипуляции по видеотраекториям. Обработка видео происходит в несколько этапов: выделение наиболее важных кадров последовательности, затем применяется метод отбора информативных визуальных токенов и соответствующих им кадров, далее добавляются аффордансы и глубина. На датасете из 500 траекторий метод различает 4 типа ошибок и успех.
-

В данной работе исследуется использование больших языковых моделей (LLM) для ответов на юридические вопросы с минимизацией галлюцинаций. Мы предлагаем фреймворк Self-Refine RAG, который расширяет стандартный подход Retrieval-Augmented Generation (RAG) модулем критики и уточнением на основе beam search.
-

В работе рассматриваются и сравниваются стратегии выбора ансамбля моделей на гетерогенных AI-рынках. Предлагается новый подход: использовать совокупную неопределенность как критерий отбора разнообразного ансамбля для решения различных задач машинного обучения.
-

Использование архитектуры трансформеров в задачах мета-обучения связано со значительными ограничениями в связи с отсутствием эффективной реализации вычисления мета-градиентов и необходимостью хранить промежуточные матрицы размером $$O(L^2)$$ для подсчета градиентов операции внимания. Предложенные методы позволяют ускорить подсчет мета-градиентов внутри трансформеров и сократить требования к памяти GPU.
-

Данное исследование посвящено решению одной из ключевых проблем современной робототехники — повышению точности интерпретации пространственных команд, передаваемых роботам-манипуляторам через интерфейсы на основе больших языковых моделей (LLM).
-

Наиболее многообещающим методом планирования траектории гуманоидного робота является её представление в виде последовательности положений и ориентаций стоп. Данные алгоритмы позволяют выполнять точный и быстрый подход к объектам интереса, а также успешно избегать столкновений с различными препятствиями. Предложенная реализация алгоритма планирования основана на методе Timed Elastic Band, позволяющем учесть не только наличие препятствий, но и кинематические особенности конкретной модели робота.
-

В работе представлен метод синтеза траектории прыжка гуманоидного робота Booster T1 на основе дифференциального динамического программирования (DDP), реализованного в фреймворке Crocoddyl. Задача сформулирована как дискретная задача оптимального управления с учетом многозвенной динамики, фаз контакта и ограничений кулоновского трения. В результате получена физически реализуемая траектория прыжка с заданной высотой и длиной, подтверждающая эффективность предложенного подхода.
-

В работе проведено исследование повышения точности локализации и картографирования в замкнутых помещениях на базе робособаки Lynx M20 Pro. Предложен подход, объединяющий лидар-инерциальную одометрию с визуально-инерциальной подсистемой в рамках алгоритма FAST_LIVO с использованием итеративного расширенного фильтра Калмана. Эксперименты показали, что добавление камерных данных снижает погрешность оценки позы и устраняет артефакты карты, повышая надежность системы.
-

В работе предложена новая роботизированная система для сборки головоломки Мегаминкс, основанная на пространственной кинематической схеме с независимым приводом каждой из двенадцати граней. Теоретический анализ показывает возможность многократного сокращения времени сборки за счет устранения вспомогательных манипуляций и перехода к параллельному исполнительному управлению.
-

В данном экспериментальном исследовании проводится оценка влияния инструктивной разметки релевантности в входном запросе на выраженность позиционной предвзятости больших языковых моделей при решении задачи вопрос–ответ по длинному контексту с контролируемым положением релевантной информации на разных моделях и языках
-

В работе пересматриваются существующие неконтролируемые метрики качества эмбеддингов и вводятся новые метрики на основе теории информации. Показано, что классические спектральные метрики — ранг, эффективный ранг и NESum — образуют единое семейство энтропий Реньи. Обширная оценка существующих и новых подходов показывает, что большинство неудач в обобщении моделей SSRL объясняются линейными дефектами эмбеддингов, а не более сложными метриками, такими как кластеризация или энтропия.
-

KM-ViPE — это система SLAM реального времени для некалиброванных монокулярных камер, которая объединяет геометрическую реконструкцию сцены с высокоуровневыми визуально-языковыми признаками DINO. Система устойчиво работает в динамических средах за счёт адаптивных робастных ядер, управляемых семантическим сходством признаков, и формирует трёхмерную карту с поддержкой запросов на естественном языке без датчика глубины, калибровки камеры и офлайн-обработки.
-
 Разработана политика четырёхконечной локомоции для гуманоидного робота K1 с использованием обучения с подкреплением в среде Isaac Gym. Применение алгоритма PPO и методов повышения робастности (доменная рандомизация, шумовая модель наблюдений) позволило успешно перенести политику на реальное устройство без дообучения. Полученные результаты могут быть использованы при создании систем управления для робототехнических соревнований, таких как HuroCup.
Разработана политика четырёхконечной локомоции для гуманоидного робота K1 с использованием обучения с подкреплением в среде Isaac Gym. Применение алгоритма PPO и методов повышения робастности (доменная рандомизация, шумовая модель наблюдений) позволило успешно перенести политику на реальное устройство без дообучения. Полученные результаты могут быть использованы при создании систем управления для робототехнических соревнований, таких как HuroCup. -

В работе предлагается формальная методология оценки экономического эффекта от внедрения больших языковых моделей (LLM) в корпоративные бизнес‑процессы, таких как клиентская поддержка, внутренний консалтинг и аналитика. Подход сочетает causal‑inference/кластерные квазиэксперименты с A/B‑тестированием и учитывает не только прямые эффекты (сокращение времени и затрат), но и косвенные метрики: качество решений, риск‑профиль и удовлетворенность пользователей.
-

В работе демонстрируется, что в условиях холодного старта при разреженных данных реранжирование не только улучшает, но и систематически ухудшает качество рекомендаций, снижая точность и сужая охваты каталога. Для решения этой проблемы представлена двухголовая архитектура ранжировщика, позволяющая восстанавливать баланс сежду точностью и серендипностью за счет совместной оптимизации этих критериев.
-

-

В работе исследуется применение обучения с подкреплением методом Group Relative Policy Optimization (GRPO) к задаче генерации графов сцены с помощью визуальных языковых моделей. Предложенная схема дообучения учитывает корректность формата ответа, качество объектов, отношений и покрытие графа. Эксперименты на датасете PVSG показали снижение доли невалидных графов и улучшение качества восстановления сцены.
-

В работе рассматривается подход к репараметризации свёрточных слоёв на основе низкоранговой декомпозиции тензора свёртки в задаче классификации изображений. Эксперименты с ResNet-18 на CIFAR-10 показали возможность сокращения числа параметров в 6.48 раз без потери точности и в 10.44 раз с минимальным снижением качества на 0.2 %. Результаты демонстрируют эффективность предложенного подхода при разработке компактных моделей.
-

В данной работе демонстрируется модификация планировщика SI-RRT для задач многоагентной манипуляции. Были выявлены проблемы, и была предложена модификация планировщика под названием SI-RRT(m) для задач приоритизированного многоагентного планирования пути манипуляторов. Эксперименты показали превосходство нового алгоритма над ST-RRT*.
-

В работе представлено исследование применимости архитектуры "трансформер" для задачи управления скелетно мышчной моделью человека, проводится сравнительный анализ ее эффективности по сравнению с MLP.
-

В работе предлагается адаптивная система фильтрации для мультиагентных диалоговых моделей, состоящая из четырёх последовательно работающих агентов. Ключевая особенность — семантическая память, которая хранит векторные представления прошлых опасных ситуаций и позволяет применять релевантные проверки к новым контекстам без переобучения. Система анализирует как входные запросы, так и генерируемые ответы, принимая решение о блокировке, переформулировании или разрешении вывода.
-

В работе представлен модульный конвейер генерации 3D семантических сцен-рафов в реальном времени на основе RGB-D данных. Подход объединяет open-vocabulary детекцию объектов (YOLOE), реконструкцию их трёхмерной геометрии и модульное предсказание пространственных отношений. Эксперименты в среде NVIDIA Isaac Sim показывают возможность построения сценовых графов со скоростью до 15 кадров в секунду.
-

Разработка веб-ориентированной платформы для автоматизации технологических собеседований, объединяющих адаптивного AI - интервьюера и интеллектуальную систему прокторинга для объективной оценки навыков кандидатов и контроля достоверности прохождения интервью
-

Распознавание рукописного текста остаётся сложной задачей из-за вариативности почерка и отсутствия чётких границ символов. Цель работы - исследовать применение трансформеров для распознавания рукописного текста и оценить их эффективность по сравнению с традиционными подходами.
-

Оценено качество 16 неконтролируемых метрик извлечения информации из 1000 судебных решений на основе 7168 экспертных оценок. Наилучшее согласие с экспертами показали метрики Term Frequency Coherence (\(r = 0,540\)) и Coverage Ratio (\(r = 0,513\)). Плотность юридических терминов (\(r = –0,479\)) коррелирует отрицательно. Метрики пригодны для первичного скрининга, но не заменяют экспертную оценку в задачах высокой точности.
-

В работе предлагается трансформерная архитектура, агрегирующая информацию о чатах на двух уровнях: уровне чата и уровне юзера. Предлагаемая модель позволила получить прирост в 16% AP при поиске фрода относительно одноуровнего решения.
-

Исследуется применение VLM для аугментации датасетов путем редактирования существующих изображений с целью компенсации дисбаланса классов в задачах классификации. Проведен сравнительный анализ влияния различных стратегий отбора изображений и других факторов на успешность аугментации датасетов CUB и iwildcam. Экспериментально показано, что предложенный подход с использованием VLM позволяет существенно повысить качество классификации, превосходя традиционные методы аугментации.
-

Работа посвящена разработке и исследованию гибридной графово-временной нейросетевой модели для онлайн-диагностики болезни Альцгеймера по потоковым ЭЭГ-сигналам. Метод сочетает временное извлечение признаков, графовую агрегацию межканальных связей и механизмы внимания, что позволяет учитывать пространственно-временную структуру ЭЭГ.
-

В работе сравнивается наивный подход к сжатию трансформерных моделей BERT и ViT с помощью SVD и более продвинутый метод на его основе — ASVD. Мы показываем, что ASVD даёт небольшое преимущество на текстовом домене, а для изображений он неотличим от базового метода из-за особенностей нормализации активаций. При этом с дообучением нам удалось сжать модель ViT втрое, потеряв лишь 7% точности. Работа выявляет ограничения ASVD как универсального инструмента для сжатия трансформеров.
-

В работе исследуется возможность обнаружения дрейфа данных в задачах классификации текстов на основе анализа распределения уверенности модели. Предложенный подход основан на применении confidence-аудитора и не требует доступа к исходным данным или их разметке. Проведена эмпирическая валидация метода на задаче анализа тональности русскоязычных текстов с использованием моделей TF-IDF и RuBERT при различных сценариях языкового дрейфа.
-

Мы рассматриваем задача прогнозирования графов сцены с открытым словарём. Мы предлагаем систему, состоящую из двух компонентов: модели открытой семантической генерации графов OvSGTR для текущего изображения и модели генерации будущих кадров FramePack. Сначала модель SGG предсказывает граф сцены для текущего RGB-изображения. Затем FramePack, используя предсказанный граф и текущий кадр, генерирует будущий RGB-кадр. Прогнозируемый граф сцены получается путём применения той же модели SGG.
-

В данной работе мы исследуем возможность применения LLM и архитектуры retrieval-augmented generation (RAG) для построения детектора prompt-атак. Особое внимание уделяется таким требованиям к системе, как адаптивность к новым данным и низкая стоимость разработки. Набор таких качеств позволит адаптировать защиту под область применения модели, а это в свою очередь позволит отсеять значительную часть вредоносных запросов. В работе приводится архитектура трех вариантов детекторов и их сравнение.
-

В данной работе представлена разработка программного модуля для сегментации облаков на спутниковых снимках, адаптированного для встраиваемых систем с ограниченными вычислительными ресурсами. В ходе исследования был проведён анализ открытых датасетов (38-Cloud, SPARCS, CloudSEN12), сравнительное тестирование архитектур (U-Net, U-Net++, DeepLabV3+, CDNet) и применена оптимизация к модели Unet, которая показала наилучшие результаты на валидации.
-

В работе исследуется возможность сократить вычислительную стоимость Chain-of-Thought без изменения весов основной языковой модели: к замороженной модели добавляется компактная обучаемая голова, генерирующая последовательность латентных векторов, которые заменяют часть токенов блока рассуждения.
-

Рассмотрены современные методы обнаружения радиопульсаров, включая компенсацию дисперсии, обеспечивающую высокое разрешение. Исследуется применение нейросетевых технологий для классификации кандидатов с подавлением помех и отбор показательных признаков. Показано, что комплексный подход, включая компенсацию дисперсии и нейросетевые методы повышают качество поиска, снижая ложные обнаружения.
-

В настоящий момент процесс разработки дизайн-концепта цифрового продукта включает множество этапов анализа со стороны дизайна. К ним относится поиск референсов, генерация цветовых палитр, подбор шрифтов и другие элементы визуальной и аналитической составляющей. Данные этапы отнимают много времени и являются трудоемкими, так как зачастую выполняются вручную, что замедляет начальное проектирование и увеличивает время на разработку продукта.
-

В работе предлагается метод построения HD-карт с использованием визуально-языковой модели. Архитектура HDMapVLM генерирует векторное представление дорожной сцены из видеопотока одной фронтальной камеры. Модель дообучена на базе Qwen3-VL и формирует структурированное описание карты в SVG-подобном формате, позволяя получать элементы HD-карты без сложной сенсорной конфигурации и дополнительной постобработки.
-

Предложена архитектура метрико-семантического SLAM, объединяющая метод пространственно-временной картографии Khronos с нейросетевой 3D-реконструкцией VGGT. Использование сквозной модели реконструкции позволяет отказаться от инерциальных датчиков и выполнять построение семантически обогащенных карт по данным только монокулярной RGB-камеры. Подход обеспечивает детальное понимание сцены и навигацию к объектам при минимальных требованиях к сенсорному оснащению.
-

Целью исследования является разработка усовершенствованного методологического подхода к раннему прогнозированию относительной силы движения финансовых активов на основе методов машинного обучения. Исследование выполнено с использованием многомерной витрины финансовых данных, включающей фондовые индексы различных регионов, секторальные индексы, валютные пары, товарные активы и индикаторы неопределенности. Приведены выводы, ограничения и допущения при разработке конвейера.
-

Разработана модель глубокого обучения с подкреплением для динамического управления инвестиционным портфелем на российском фондовом рынке, использующая 5-минутные данные торгов и тональность новостей. Предложенный подход демонстрирует значительное преимущество над стратегией Buy-and-Hold в кризисные периоды 2021-2022 гг., снижая максимальную просадку и обеспечивая избыточную доходность за счет адаптивной ребалансировки активов.