68-я Всероссийская научная конференция МФТИ
Список разделов ФПМИ - Секция алгоритмов и технологий программирования
Секция посвящена алгоритмам и технологиям программирования
Контакты:apply@atp-fivt.org
Формат проведения: онлайн
Дата и время проведения: 31.03.2026 в 11:00
Место проведения: МФТИ
-

Разработка игр требует взаимодействия команд художников и техников. Для этого в движки часто вводят высокоуровневые ЯП по типу Lua.
С распространением ECS, принципиально отличной модели представления игровых объектов от классического ООП подхода, задача интеграции ЯП в проекты стала сложнее.
Работа представляет собой интрпретатор надмножества Lua с рядом улучшений, встраиваемый в проекты с ECS и позволяющий писать код с минимальным оверхедом. -

Диффузионные модели для улучшения разрешения изображений (Super Resolution, SR) обеспечивают высокое визуальное качество изображений, но требуют десятков шагов модели, что делает их медленнее других SR-решений. Цель работы - получить одношаговую диффузионную SR-модель, которая сравнима с лучшими одношаговыми T2I-подходами, сохраняет достоверность деталей, но при этом остается компактной и вычислительно экономичной.
-

В данной работе представлена система оценки физических рисков стихийных бедствий, предназначенная для интеграции в процессы андеррайтинга и стресс-тестирования финансовых институтов. Предлагаемый подход использует архитектуру «снизу-вверх», осуществляя оценку потенциального ущерба на уровне отдельных объектов инфраструктуры с агрегацией до портфельного уровня. Валидация системы на ретроспективных данных подтвердила несмещенность оценок и повышение точности оценки.
-

Основной предмет исследования - распределённая структура данных для детерминированной параметрической реконфигурации микросервисных систем на основе иерархии ролей и кэшируемого конечного автомата с несколькими уровнями хранения данных конфигураций приложений, содержащих различные свойства для управления работой сценариев сервисов.
-

Целью данной работы является разработка оптимального алгоритма потоковой передачи данных, минимизирующий стоимость обработки и хранения как локальных, так и удаленных сегментов на S3 в зависимости от входящей потоковой нагрузки, с использованием многоуровневого хранилища на основе Apache Kafka.
Оптимизационная задача формулируется как минимизация функции TCO в зависимости от гиперпараметров при ограничениях заданного перцентиля производительности
-

Данная работа обобщает результаты систематического обзора литературы (СОЛ), охватывающего 47 первоисточников (2020 – 2025 гг.), с целью представить лучшие практики моделирования и верификации надежности систем на основе систем машинного обучения (СМО), тем самым сокращая разрыв между академическими исследованиями и внедрением в промышленности.
-

近期研究强调了机器学习系统(MLS)组件固有的脆弱性和威胁,但缺乏对MLOps环境基础设施特有风险的分析。本研究通过系统分析部署在高等经济学院(HSE University)的MLOps平台流水线中的威胁,填补了这一空白。本研究结合了STRIDE方法论和考虑机器学习对抗性因素的方法,以分析脆弱性、识别威胁并概括缓解策略。
-

В данной работе представлена система разработку гибридной системы процедурной генерации реалистичных природных ландшафтов с растительностью для виртуальных окружений, которая преодолевает ограничения классических методов (фрактальные шумы, статическое размещение объектов) за счёт интеграции GPU-вычислений и агентного моделирования, обеспечивая динамическую связь между рельефом, гидрологией, инсоляцией и биологическими процессами роста растений.
-

Разработан метод эффективного сжатия резервных копий, интегрирующий современные алгоритмы с LSM-деревом. Архитектура разделяет синхронную запись и асинхронную оптимизацию хранения. Решение позволяет достичь высокой скорости записи, большого коэффициента сжатия и поддерживает гранулярное восстановление блоков. Экспериментальная реализация подтверждает производительность и практическую применимость метода.
-

В докладе представлен программный комплекс автоматизации разработки uplift-моделей, оценивающих инкрементальный эффект воздействия. Предложенное решение интегрирует все основные этапы построения и эксплуатации модели от обработки данных до мониторинга качества во время использования в промышленных бизнес-системах. Данный программный комплекс ускоряет переход от тестирования гипотез к эксплуатации моделей в 5–10 раз с 5-7 дней до 4-8 часов при сохранении высокой точности прогнозов.
-

В данной работе предлагается новый гибридный подход к решению задач составления расписаний учебного заведения, включающий в себя алгоритм коллапса волновой функции для получения приемлемого решения, удовлетворяющего жёсткие ограничения, а также последующую оптимизацию решения генетическим алгоритмом.
-

В работе исследовано планирование задач в DAG при ограниченном пуле ресурсов. На основе дискретно-событийного моделирования показано, что при редких дедлайнах, смещённых к концу графа, эвристики критического пути (HEFT/PEFT) уменьшают и makespan, и суммарную просрочку по сравнению с остальными правилами.
-

Задача поиска дефектов в коде входит в число ключевых для анализа бинарного кода. Для её решения анализируют состав программного обеспечения - композиционный анализ. Для композиционного анализа важно уметь определять версии использованных продуктов. Эфективнее всего это делать при помощи анализа изоморфизмов графов потока управления и графов вызова. Эта задача принадлежит классу NP. В даннной работе предствалена реализация ускоренного поиска позволяющего сузить область для точного поиска.
-

Яндекс реклама обрабатывает миллионы запросов в секунду. Для этого требуется много железа. Поэтому нам надо экономить его очень сильно и не растрачивать попусту. В работе рассматривается конкретный способ построения оптимальной шардированной архитектуры, с помощью которой планируется соптимизировать 10000 ядер cpu, что в пересчете на деньги, согласно Yandex Cloud, составляет около 14 млн. р.
-

Для исследований с использованием искусственного интеллекта возникает потребность в большем числе гетерогенных данных. Так, одним из решением является data lake (озеро данных) — неструктурированное хранилище данных, однако такой подход затрудняет процесс работы с данными. Работа фокусируется на создании сервиса интеграции, предоставляющего возможность структурированного доступа к информации и поддерживающего автоматическую синхронизацию локальных изменений.
-

В данной работе получил дальнейшее развитие метод словарного сжатия данных при передаче в распределённых системах, отличающийся от существующих подходов тем, что объединяет (1) механизм инкрементального обновления словаря "на лету", и (2) способ согласованного обновления словарей у отправителя и получателя, что позволяет автоматически поддерживать коэффициент сжатия близким к оптимальному при дрейфе данных и достигать экономии сетевого трафика кластера.
-
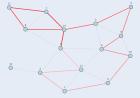
В работе рассматривается проблема применения классического алгоритма муравьиной колонии (ACO) к задаче поиска максимального цикла на неполном орграфе. Показано, что стандартный подход приводит к стагнации алгоритма в локальных оптимумах. Предложена модификация алгоритма, включающая новую математическую формулировку, введение памяти маршрутов, а также иную формулу рассчета взноса феромона на вершины. Эффективность алгоритма оценивалась в симуляциях в сравнении с классическими алгоритмами.
-

Разрабатывается сервис управления виртуальными машинами, который позволяет по шаблону создавать группу виртуальных машин и обновлять их по модели Blue-Green deployment. Сервис автоматизирует создание, обновление и откат инфраструктуры, снижая риск ошибок и обеспечивая более надежный выпуск изменений
-

В работе исследуется возможность обнаружения дрейфа данных в задачах классификации текстов на основе анализа распределения уверенности модели. Предложенный подход основан на применении confidence-аудитора и не требует доступа к исходным данным или их разметке. Проведена эмпирическая валидация метода на задаче анализа тональности русскоязычных текстов с использованием моделей TF-IDF и RuBERT при различных сценариях языкового дрейфа.
-

Алгоритм HNSW (Hierarchical Navigable Small World) широко применяется в индустрии для решения задачи поиска приближенных ближайших соседей (ANN) в некотором множестве объектов. Однако при удалении части объектов, на которых был построен индекс HNSW, требуется полное перестроение индкса с нуля. В данной работе представлен алгоритм, который позволяет удалять из индекса HNSW произвольные объекты без деградации качества поиска ближайших соседей.