Для обеспечения корректной работы игрового сервиса необходимо анализировать историю пользовательских действий. В работе исследуется способ выявления аномалий в пользовательской активности.
Секция нацелена на взаимодействие исследователей различных уровней, решающих проблемы анализа данных, распознавания образов и прогнозирования в современных прикладных и теоретических задачах.
Контакты :grabovoi.av@mipt.ru
Формат проведения:
Дата и время проведения:
Место проведения:

Работа посвящена сравнению моделей Seq2Seq LSTM и Temporal Fusion Transformer для многогоризонтального прогнозирования неисправностей в системах жизнеобеспечения зданий. Показано, что обе модели обеспечивают высокую точность, однако TFT демонстрирует лучшие результаты на 24-часовом горизонте и большую сезонную устойчивость.

В работе рассматривается состязательная архитектура солвера для нахождения численных решений дифференциальных уравнений в частных производных(ДУЧП). Архитектура состоит из двух нейронных сетей, в первой из которых, аппроксимирующей решение ДУЧП, предлагается заменить функции активации на бесконечно гладкие. Это обеспечивает более высокую скорость сходимости.

Предложен гибридный подход к восстановлению 3D-рельефа мазков по одному 2D-изображению. Метод комбинирует структурный тензор для анализа текстуры и нейросеть U-Net для сегментации мазков и оценки градиентов высоты. Восстановление поверхности выполняется методом Frankot–Chellappa в частотной области. Результат — карта высот и STL-модель для тактильных копий и искусствоведческого анализа без доступа к оригиналу.

Представлен гибридный подход к прогнозированию многомерных временных рядов в условиях малых и шумных данных, объединяющий структурную кластеризацию и фундаментальные модели временных рядов. Метод обеспечивает устойчивое условное прогнозирование и улучшение качества по сравнению с традиционными VAR-моделями.

В работе исследуется сходимость ландшафта функции потерь архитектуры трансформер при увеличении объема обучающей выборки. Проведен теоретический анализ матрицы Гессе для блока self-attention и полного трансформер-блока с использованием аппроксимации второго порядка и разложения Гаусса–Ньютона. Получена оценка разности эмпирических функций потерь при переходе от k к k + 1 обучающим примерам. Теоретические результаты подтверждены экспериментально на датасете CIFAR-100.
В работе предложен метод построения ансамблей нейронных сетей с явным контролем компромисса между индивидуальной точностью моделей и их разнообразием. Метод основан на двух суррогатных функциях, предсказывающих точность архитектур и их предиктивное разнообразие в латентном пространстве. Эксперименты на FashionMNIST, CIFAR-10 и CIFAR-100 подтверждают превосходство подхода над базовыми методами.

В данном исследовании представлен комплексный анализ будущей пригодности сельскохозяйственных земель на основе климатических прогнозов до 2050 года с использованием современных методов машинного обучения.Результаты исследования демонстрируют, что общая площадь земель, пригодных для сельского хозяйства, прогнозируется к увеличению, расширяясь на север. Однако некоторые из ныне используемых сельскохозяйственных регионов могут потребовать увеличения орошения, что создаёт потенциальные риски.

В работе исследуется процесс дообучения языковой модели RuBERT на текстах в предментой области системной инженерии. При дообучении применяется расширение токенизатора, а эффективность добавления новых токенов в применении к задаче классификации отслеживается с помощью метода SHAP, что позволяет взглянуть на процесс обучения с новой стороны.

Рассматривается задача векторизации (построения векторных представлений) семейства генеративных моделей, обученных на различных подвыборках объектов без явной разметки классов. Предлагается двухэтапный подход: сначала обучается дискриминатор на уровне распределений, измеряющий расхождение между порожденными выборками двух моделей посредством максимального среднего расхождения (MMD). Затем полученная мера используется для обучения векторизатора моделей.

В работе предлагается новая постановка задачи обнаружения визуального плагиата—предсказание последовательности преобразований, позволяющей получить одно изображение из другого. В отличие от методов попарного сравнения векторных представлений, предложенный подход состоит в предсказании последовательности токенов-преобразований, обеспечивающей доказательное объяснение связи изображений. Эксперименты показывают улучшение качества по сравнению с традиционными методами и современными VLMs.

В работе рассматривается задача построения векторных представлений генеративных моделей, согласованных с геометрией распределений данных, на которых они обучены. Предлагается рассматривать семейство генеративных моделей как точки в пространстве, структура которого должна отражать композицию лежащих в основе подраспределений данных.

В работе рассматривается задача оценки сходимости ландшафта функции потерь при увеличении размера выборки. Предлагается среднеквадратичный критерий, контролирующий изменение поверхности функции ошибки в наборе точек. Обосновывается переход к подпространству главных собственных векторов матрицы Гессе нейронной сети. Доказывается теорема о корректности предложенного критерия. Проводится вычислительный эксперимент на задаче классификации изображений.

В данной работе будут рассматриваться некоторые подходы детекции и треккинга объектов на фото-/видео- данных полученных с БПЛА, которые ложатся в основу разработки навигационного интеллекта.

В работе представлено исследование на тему оценки функционального состояния профессиональных атлетов. Описываются все шаги исследования - от сбора данных до статистического анализа и обучения модели прогнозирования максимального потребления кислорода (МПК) у спортсменов. Также рассказывается про созданную в рамках работы цифровую платформу для поддержки принятия решений врачами спортивной медицины.

В данной статье предлагается использовать метод на основе графовой суррогатной модели, основанной на вычислительном графе исходной нейронной сети, и оценке информационного потока, распространяющегося по нему. Метод позволяет оценить важность операций на графе вычислений во few-shot подходе, то есть с использованием нескольких проходов небольшого подмножества данных через модель.
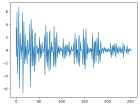
В работе исследуются способы создания признаковых пространств из сигнатурных представлений многомерных путей для извлечения скрытых связей в многомерных временных данных. На примере рассмотренных задач анализа временных рядов экспериментально доказано, что применение сигнатурных представлений позволяет нейросетевым моделям создавать более богатые признаковые пространства, хранящие информацию о структуре временных данных.

В работе исследуется задача декодирования визуальной информации из сигналов мозга. Предложена методология декодирования визуальных стимулов по сигналам фМРТ и ЭЭГ, учитывающая пространственно-временные характеристики и индивидуальную гемодинамическую задержку.

Данная работа посвящена сравнительному анализу статических и динамических методов векторизации текста для реализации семантического поиска в корпусе классических латинских текстов. Исследование направлено на выявление оптимальных стратегий представления текстовой информации, обеспечивающих баланс между качеством поиска и вычислительной эффективностью в условиях ограниченных данных и высокой предметной специфики античных источников.

В работе рассматривается задача выделения сигналов мониторинга физиологических параметров из данных инерциальных датчиков. Предложен метод многомерной декомпозиции сигналов на основе сингулярного разложения матрицы Ганкеля.

В работе предлагается интерпретируемый ленивый метод классификации для числовых данных на основе Интервальных Узорных Структур. Алгоритм расширяет k-NN, формируя для каждого объекта гиперпрямоугольник как локальное объяснение решения. Используется отбор признаков на основе информационного выигрыша и оценивается их важность. Эксперименты на открытых наборах данных показали сопоставимое качество по F1-мере с k-NN при большей интерпретируемости модели.

Данная работа посвящена исследованию анизотропии в трансформерах — явлению, при котором вектора представлений токенов сближаются, выстраиваясь вдоль одного или нескольких направлений. В ходе экспериментов была изучена динамика анизотропии под действием различных преобразований слоев трансформеров, и обнаружено, что наиболее высокие значения анизотропии наблюдаются после добавления остаточных связей.

Работа посвящена нейросетевому приближённому решению 2D уравнения Гельмгольца в неоднородной среде. Поле аппроксимируется Kolmogorov–Arnold Network (KAN). Для устранения сингулярности точечного источника используется разложение (U=U_0+u) и условие Зоммерфельда на границе. Показано качественное совпадение с эталонным численным решением.

Работа посвящена оценке аугментаций ATR-FTIR-спектров биожидкостей. Основной объект — жидкость десневой борозды (ЖДБ), т.е. жидкость между зубом и десной, отражающая состояние пародонта; выборки ЖДБ обычно очень малы, и модели легко переобучаются. Сравниваются baseline (без аугментации) и train-only аугментации (шум, сдвиг, Mixup) по метрикам, геометрии данных (PCA) и QC; дополнительно сопоставляются результаты на слюне (COVID-19, diabetes).

Работа посвящена прогнозированию успешности удовлетворения информационной потребности пользователя в генеративных поисковых системах (RAG). Предложена регрессионная модель, оценивающая ожидаемое значение продуктовой метрики по поисковым запросно-документным признакам до запуска языковой модели. Эксперименты на данных промышленной системы показали высокую корреляцию с реальным онлайн-сигналом и лучшую калибровку по сравнению с моделями награды.

Работа посвящена предсказанию изменений фМРТ-сигнала по внешнему стимулу при ограниченных данных. Предложен интерпретируемый линейный подход, связывающий признаки стимула с гемодинамическим ответом и пригодный для персонализированного анализа без больших вычислений. Также показано, что фокус на релевантных зонах мозга делает оценку отклика устойчивее. Эксперименты подтверждают связь стимула и фМРТ и также демонстрируют, что объединение аудио и видео улучшает прогноз по сравнению с одним каналом.
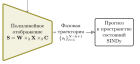
Исследование посвящено разработке подхода к идентификации функций эволюции для семейства динамических систем на основе анализа многомерных временных рядов. Основная цель — создать метод совместного обучения по набору временных рядов, позволяющий одновременно восстановить нелинейные зависимости динамики и параметризовать их вектором параметров с использованием полилинейного отображения в фазовое пространство.


Предлагается метод для автоматического поиска архитектуры для смеси экспертов. Метод состоит в том, что обучается суррогатная функция для предсказания качества работы архитектуры на каждом кластере данных. Доказывается теорема о применении EM алгоритма для нахождения оптимального разбиения данных на кластеры и подбора эффективной архитектуры для каждого кластера. В каждой итерации алгоритма используется полученная суррогатная функция для оценки правдоподобия данных.

Разработка методики ускоренных испытаний аккумуляторных батарей путем сокращения времени испытаний с использованием методов машинного обучения. Обучающие и валидационные данные сформированы на базе физической модели аккумулятора в Amesim.

Работа посвящена математическому моделированию и анализу петли обратной связи в рекомендательных системах — процесса, при котором алгоритм обучается на данных, сгенерированных им же на предыдущих итерациях.
Главным научным результатом является строгое доказательство достаточных условий формирования многомодальной эхо-камеры. Показано, что под воздействием L2-регуляризации оператор перехода становится сжимающим.

Целью работы является разработка модели машинного обучения, предназначенной для прогнозирования состояния здоровья литий-ионной аккумуляторной батареи (АБ). Модель обучается на исторических данных циклов заряда-разряда и применяется для оценки остаточного ресурса на новых циклах эксплуатации при различных температурах.

В работе решается задача быстрой адаптации универсальных текстовых эмбеддингов к инструкциям без пересчёта корпуса. Мы обучаем линейное преобразование и сохраняем более 80% прироста качества инструкционного режима (47.7 из 58.5 п.п.). Уже на 8 тыс. текстов получаем 4× ускорение, а с ростом данных выигрыш масштабируется (41× на 120 тыс.) и продолжает расти. По мере усиления моделей абсолютный эффект также увеличивается (от ~5 до ~47 п.п.), что подтверждает масштабируемость метода.

В работе предлагается метод Categorical Schrödinger Bridge Matching для построения мостов Шрёдингера в дискретных пространствах и решения задачи непарного переноса домена. Метод опирается на строгий теоретический результат для дискретного случая, что делает применимой итеративную марковскую процедуру D-IMF. Эксперименты на задаче перевода домена подтверждают преимущество подхода по стандартным метрикам качества.

Оценка сложности моделей машинного обучения является ключевой задачей при их выборе для решения прикладных задач. Спектральные свойства матриц Гессе количественно оценивают кривизну оптимизационного ландшафта и определять сложность оптимизации параметров параметрических моделей. В работе исследуется ландшафтная мера сложности моделей, которая определяется через спектральные свойства матриц Гессе функции потерь и отражает изменение кривизны ландшафта при расширении набора данных.

Работа посвящена распознаванию текстов русской дореформенной орфографии на материале решений Уголовного кассационного департамента Правительствующего Сената за 1914 год. Исследование направлено на сравнение традиционного OCR на базе ABBYY FineReader и VLM-подходов, а также на разработку методики оценки качества распознавания исторических документов.

Разработан гибридный метод восстановления нейтронного спектра по данным со спектрометра Боннера на основе сетей глубокого развертывания (DUN) с MLP-блоками, решающий некорректную обратную задачу. Архитектура состоит из 15 слоёв развертки с встроенным MLP и многокомпонентной функцией потерь. В результате тестирования на 251 спектре из компендиума МАГАТЭ с внесенным 5% шумом метод показал R²=0,86, RMSE=0,047 и ошибку по дозе 6,87%, превосходя обычные MLP модели.

В работе проводится систематическое сравнение эмбеддинг-моделей на задаче выявления интертекстуальных связей в латинском эпосе. Сравнение проводится на датасете интертекстов из первой книги "Аргонавтики" Валерия Флакка. Установлено, что дообученные модели значимо превосходят универсальные, при этом наиболее трудным типом для различения оказываются фрагменты того же автора, не являющиеся интертекстами.

В работе предложен подход к мульти-лейбл классификации коротких рекламных текстов в условиях сильного дисбаланса классов на основе семантической дистилляции знаний. Обучение RuBERT на псевдоразметке, сгенерированной QWEN, позволяет компенсировать дефицит обучающих примеров для редких категорий нарушений. Показано, что перенос знаний обеспечивает прирост метрики Macro F1 и восстанавливает способность модели выявлять миноритарные классы при сохранении высокой скорости инференса.

Разработан и реализован конвейер подготовки данных из видео для анализа движений человека: извлечение 2D-позы, трекинг, очистка и нормализация, формирование последовательностей и расширение выборки. Качество предобработки и информативность признаков проверяются на нескольких моделях (Decision Trees, Transformer, Mamba).

Исследуются механизмы внутреннего информационного обмена в гибридных пространственно-временных нейросетевых архитектурах вида CNN-LSTM и ViT-LSTM на примере задач видеоаналитики и анализа медицинских данных фМРТ

В работе исследуется автоматическая детекция эпилептиформной активности на ЭЭГ с использованием YOLOv8 и YOLOv10. Фрагменты ЭЭГ преобразуются в изображения для локализации патологических событий. Рассмотрены задачи детекции эпилептиформной активности и совместной детекции с артефактами. Также исследована многозадачная модель с дополнительной классификацией канала, содержащего доминирующее патологическое событие.

В работе предложен нейросимвольный конвейер для извлечения формальных структур из корпуса методик расчёта фондовых индексов. Конвейер сегментирует документ, классифицирует фрагменты по автоматически индуцированной таксономии и строит граф зависимостей терминов с детерминированной верификацией согласованности. Показано, что подавляющая доля фрагментов обрабатывается детерминированно, а пилотная верификация выявляет структурные несоответствия с трассируемостью до строки источника.

Цель работы — разработка интерфейса для сравнения научных статей, позволяющего оценивать актуальность прикрепленных ссылок

В работе предлагается решение для задачи оптимального одно модельного моделирования векторного поля для задачи трансляции КТ-изображений. Предлагается подход для покомпонетной инъекции времени в модель, и сверточный механизм вниманий в бутылочном горлышке сверточной сети для учета более сложных зависимостей.

В данной работе предлагается метод оценки сложности, основанный на анализе геометрии распределения данных. В качестве инструмента извлечения геометрических характеристик используются современные глубокие генеративные модели, в частности диффузионные модели на основе скор-функции. В работе рассматривается мера сложности, которая удовлетворяет ряду теоретических свойств.

Рассматривается задача восстановления парных зависимостей по данным, наблюдаемым в виде групп двух непарных наборов и ; предложено усовершенствовать вероятностную постановку, аппроксимируя латентную перестановку сглаженной матрицей перестановки в рамках категориального вариационного автоэнкодера, используя Gumbel-Softmax для дифференцируемости выборки и Sinkhorn-оператор для обеспечения биективности соответствий.

Разработана нейросетевая модель, позволяющая регулярно получать актуальную карту землепользованиядля территории России в легенде IPCC-6 по данным Sentinel-2 (10 м). Модель выполняет семантическую сегментацию спутниковых снимков на классы, пригодные для мониторинга изменений земной поверхности. Качество оценивается по метрикам IoU и F1. Решение ориентировано на задачи климатической отчётности (MRV), оценки углеродного баланса и оперативного обновления карт по мере поступления новых снимков.

Работа посвящена разработке программного комплекса для автоматизированной обработки библиотечных карточек и карт сохранности редких изданий с формированием данных в формате RUSMARC, включая поддержку карточек без графических разделителей и улучшенные алгоритмы сегментации текста и извлечения информации.

В работе исследуется применение Self-supervised learning (SSL) метода для классификации целевых и нецелевых стимулов в интерфейсах мозг–компьютер на волне P300. Энкодер предобучается на неразмеченных ЭЭГ-данных и затем дообучается на индивидуальных калибровочных выборках. Показано, что SSL повышает качество при умеренной и полной калибровке, однако не обеспечивает стабильного снижения её минимального объёма.

В работе рассматривается задача пронозирования перемещений самокатов сервиса аренды. На основе данных о поездках, парковках и погодных условиях строится пространственно-временная модель, способная предсказывать эти перемещения на следующий день. Полученные прогнозы используются для оценки ожидаемого распределения самокатов по парковкам в начале дня и будут служить входными данными для дальнейших исследований и прикладных задач, включая построение транспортной модели и ребалансировки самокатов.

Цель данной статьи - проанализировать взаимосвязь между ЭЭГ и фМРТ путём кодирования данных обоих методов в общее латентное пространство, а также применить статистические тесты для исследования их взаимной зависимости
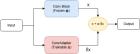
Данная работа посвящена изучению возможности применения сверточного адаптера Conv-Adapter в составе детектора YOLOv8 для решения задачи адаптации модели к изменениям условий видеосъемки. Архитектура Conv-Adapter представляет собой bottleneck-структуру с понижающей и повышающей размерность свертками и нелинейной активацией, идентичной активации базовой сети. При проведении экспериментов адаптер подключался параллельно сверточным блокам сети извлечения признаков (backbone) YOLOv8.
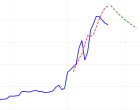
В работе рассматривается задача квартального прогнозирования средней цены 1 кв. м на первичном рынке жилья в Российской Федерации. Основной акцент сделан на построении многомерной модели BiLSTM, использующей макроэкономические и региональные признаки; топологические характеристики временного ряда рассматриваются как дополнительный источник информации, способный дать умеренное улучшение качества.

В данной работе представляется модель прогнозирования временного ряда, учитывающая пространственные взаимосвязи сигнала. Данные представляют многомерный временной ряд ЭЭГ. Современные модели неэффективно учитывают пространственную информацию, предлагается использовать графовое представление связей между источниками сигнала, что позволит учитывать сложные паттерны активности. Рассматривается несколько вариантов построения связей: в виде неориентированного и ориентированного графа.

Предложен метод улучшения сегментации 3D микро-КТ данных сверхвысокого разрешения с использованием фундаментальной модели MedSam2 в условиях отсутствия размеченных данных. Разработан пайплайн предобработки, включающий шумоподавление алгоритмом Noise2Void2 и повышение контраста, что позволило визуально улучшить качество сегментации без дообучения модели. Подход демонстрирует возможность адаптации фундаментальных моделей к специализированным данным.

Работа посвящена разработке модели многоклассовой стратификации хронической болезни почек на основе неинвазивных данных, полученных из медицинских карт пациента.
Исследование выполнено на базе датасета MIMIC-IV и включает 9712 пациентов с данными первичной госпитализации.
В качестве признаков отобраны антропометрические и клинические показатели.
Проведено сравнение логистической регрессии и ансамблевых методов.
Предложен метод ImprovEvolve, интегрирующий эвристику basin-hopping в процесс эволюционной генерации кода языковыми моделями (LLM). Декомпозиция задачи на этапы инициализации, локального улучшения и возмущения снижает нагрузку на модель, избавляя её от необходимости реализовывать полный цикл глобального поиска. Метод показал высокую эффективность, обновив мировые рекорды (state-of-the-art) в задачах упаковки гексагонов и втором автокорреляционном неравенстве.

Работа посвящена применению современных моделей эмбеддингов для семантического анализа сенатских решений Российской империи конца XIX – начала XX века. На корпусе из 54 решений выполнены предобработка, перевод на современный русский язык, векторизация с использованием модели ruBERT-ruLaw и визуализация семантического пространства методом t-SNE. Исследование направлено на выявление тематических кластеров, их связи с типом вердикта и поиск возможных аномалий в структуре судебных решений.
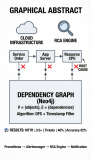
Разработана граф-ориентированная система RCA для мониторинга облачных инфраструктур. Инфраструктура моделируется ориентированным графом зависимостей трёх уровней. Алгоритм анализа первопричин использует DFS с учётом временных меток, обеспечивая линейную сложность O(|V|+|E|). Интеграция с Prometheus–Alertmanager на гибридной инфраструктуре показала: MTTR сократился в 3,5 раза (38→11 мин), обращения в поддержку уменьшились на 46%, точность RCA составила 82%.

Работа посвящена преобразованию слабоструктурированных биографических данных в машиночитаемый формат и их анализу. Рассматривается подход к обработке табличных источников с высокой вариативностью форматов записи, основанный на формализованных правилах и возможностях применения недетерминированных методов. Полученный корпус данных позволяет применять методы анализа данных и искусственного интеллекта для выявления статистических закономерностей и изучения характеристик исторических персоналий.

Представлен подход к автоматической детекции ошибок при выполнении приседаний. Предложен конвейер обработки видео с детекцией ключевых точек YOLO-Pose и формированием 8 биомеханических признаков. Для классификации использована логистическая регрессия с L2-регуляризацией, достигнута точность 78% на выборке из 23 примеров, проведена интерпретация значимости признаков.

В работе исследуется применимость методов обучения без учителя для вибрационной диагностики вращающегося оборудования. Рассматривается три подхода: реконструкция сигнала, прогнозирование сигнала, кластеризация признаков сигнала. Входные данные: сигнал, его спектр или спектрограмма. Лучший результат показывает подход реконструкции спектра сигнала.

В рамках работы был разработан универсальный пайплайн для создания модели предсказания вовлеченности (число лайков, комментариев и распределение их настроений: добрые, нейтральные, злые) для паблика в социальной сети ВКонтакте


Представлен метод синолитических графовых нейросетей (SGNN) для анализа многомерных биомедицинских данных. SGNN преобразуют выборки в графы через ансамбли парных классификаторов. Благодаря топологическим дескрипторам узлов модель достигла ROC-AUC 92.22, превзойдя XGBoost. Модель устойчива к шуму и дефициту данных (стабильна при 10% выборки). Эффективность подтверждена на данных UCI и протеомике рака. SGNN эффективны для малых клинических выборок.

В представленной работе осуществлено сравнение устойчивости ансамблевых методов машинного обучения — случайного леса, LightGBM и CatBoost — к шумовым возмущениям в задачах бинарной и многоклассовой классификации.

В работе получены первые известные оценки сходимости метода M-SignSGD при (L₀, L₁)-гладкости и шуме с тяжелыми хвостами и зависимостью от параметров. В случае стандартной гладкости эти результаты также являются новыми для знаковых методов. Результаты валидируются и применяются при обучении BERT-like модели. В заданных условиях метод с предложенной нами настройкой демонстрирует более быструю сходимость по сравнению с классическими методами.

В работе предлагается индекс аномальной активности предприятий на основе микроданных финансовой отчётности российских фирм. Индекс рассчитывается через робастную стандартизацию ROE и прокси-производительности, отражая отклонения от типичных значений внутри отраслей и регионов с последующей агрегацией до региона. Результаты регрессионного анализа выявляют статистически значимую положительную связь между индексом аномальной активности предприятий и уровнем региональной безработицы.

Разработан и протестирован офлайн-бенчмарк для сравнения малых LLM в задаче суммаризации изменений КИД фондов. На датасете из 1388 последовательных пар версий (старая_версия -> новая_версия) сопоставлены qwen2.5:3b, llama3.2:3b, gemma2:2b. Качество оценивалось judge-моделью по точности, полноте и уровню галлюцинаций. Лучший баланс метрик показала gemma2:2b; предложен каскадный контур «генератор + judge-проверка» для сервиса уведомлений.

В работе исследуется оптимизация параметров Фурье- и вейвлет-преобразований для подавления шумов в 12-канальных ЭКГ-записях на основе базы данных PTB-XL. Показано, что оптимизация параметров БПФ не приводит к улучшению результатов по сравнению с базовой конфигурацией, тогда как оптимизация параметров вейвлет-преобразования снижает морфологические искажения и повышает точность детекции R-пиков.

Разработан алгоритм автоматической сегментации и классификации сельскохозяйственных культур по спутниковым снимкам с минимальной потребностью в размеченных данных. Подход обеспечивает применимость в условиях РФ без создания масштабных обучающих выборок вручную.

В работе исследуется возможность обнаружения дрейфа данных в задачах классификации текстов на основе анализа распределения уверенности модели. Предложенный подход основан на применении confidence-аудитора и не требует доступа к исходным данным или их разметке. Проведена эмпирическая валидация метода на задаче анализа тональности русскоязычных текстов с использованием моделей TF-IDF и RuBERT при различных сценариях языкового дрейфа.

Представлено сравнение трёх методов извлечения библиографии: RedUpAPI, GROBID и Qwen. Задача включает детектирование раздела, извлечение сносок и их структурирование. Эксперименты на открытом наборе данных показали, что GROBID лучше извлекает ссылки (F1=0,97), а RedUpAPI — выделяет авторов (F1=0,93). Результаты полезны для формирования обратного библиографического списка.

В работе сравниваются три пространства retrieval для retrieval-augmented прогнозирования временных рядов: embedding-признаки foundation-модели, FFT-признаки и wavelet-признаки. Для каждого варианта оцениваются точность прогноза и вычислительная эффективность поиска соседей, в том числе при использовании FAISS/IVF. На ETTh1 показано, что embedding-based retrieval неэффективен, FFT минимизирует задержку, а wavelet даёт лучшее качество среди retrieval-методов

Авторами предлагается новый метод исследования электроокулографических сигналов для дифференциальной диагностики болезни Паркинсона и эссенциального тремора. В ходе работы проанализированы AUC-диаграммы, демонстрирующие количественное отличие локальных максимумов при сравнении двух групп пациентов

В работе рассматривается метод повышения эффективности мультиагентной торговой системы на основе мета-агента с инструментами каузального анализа. Мета-агент выявляет источники деградации в графе вычислений и выполняет адресную корректировку архитектуры, что способствует росту доходности и улучшению риск-скорректированных показателей.

В работе предлагается метод Martingale Rainbow Deep Q-Network (MR-DQN) для решения задач optimal stopping в финансах. Подход объединяет теорию мартингалов и distributional reinforcement learning, добавляя риск-метрики CVaR. Модель расширяет Rainbow DQN и обеспечивает корректность с точки зрения риск-нейтрального ценообразования. Эксперименты на криптовалютах показывают более высокую risk-adjusted доходность по сравнению с Rainbow DQN и IQN.

В работе предлагается метод Martingale Rainbow Deep Q-Network (MR-DQN) для решения задач optimal stopping в финансах. Подход объединяет теорию мартингалов и distributional reinforcement learning, добавляя риск-метрики CVaR. Модель расширяет Rainbow DQN и обеспечивает корректность с точки зрения риск-нейтрального ценообразования. Эксперименты на криптовалютах показывают более высокую risk-adjusted доходность по сравнению с Rainbow DQN и IQN.

Работа посвящена исследованию точности определения положения камеры при использовании цветных плоских шаблонов на основе фидуциальных маркеров. Рассмотрен метод поканальной обработки изображения двухцветного маркера, направленный на повышение устойчивости и точности оценки ориентации. Экспериментальное исследование выполнено на основе видеоданных, полученных откалиброванной камерой. В качестве метрики точности использован угол относительного поворота.

В данной работе предлагается подход многоэтапного обучения LLM-моделей различных архитектур для решения задач, требующих обработки длинных входных последовательностей, с использованием синтетического набора данных и критерия ранней остановки на основе промежуточных валидаций. Этот подход позволил сократить общее время обучения моделей более чем в 2 раза. Представлено сравнение численных результатов тестирования моделей Mamba, RMT и Transformer-XL

Выступая в роли информационного посредника в коммуникациях между центральным банком и населением, СМИ влияют на осведомлённость и восприятие населением центрального банка. В связи с этим возникает необходимость исследования транслируемого отношения к ЦБ в средствах массовой информации. Целью настоящей работы является разработка метода оценки эмоционального восприятия центрального банка на основе анализа аудиоданных СМИ.

Проект посвящён автоматизированному выявлению политических манипуляций в русскоязычных новостных текстах с использованием методов обработки естественного языка и машинного обучения. Промежуточные результаты включают концептуализацию и операционализацию понятия манипуляции на уровне предложения, первые версии корпуса и схемы разметки, а также пилотные эксперименты с базовыми моделями, показывающие потенциал синтетического расширения данных для повышения качества классификации.